

Clinikk x Medblocks | Designing for Subscription-Based Primary Care
Here's how Medblock's partnered with Clinikk to build a longitudinal, openEHR-based EHR that supports their novel subscription-based care model.
June 19, 2026
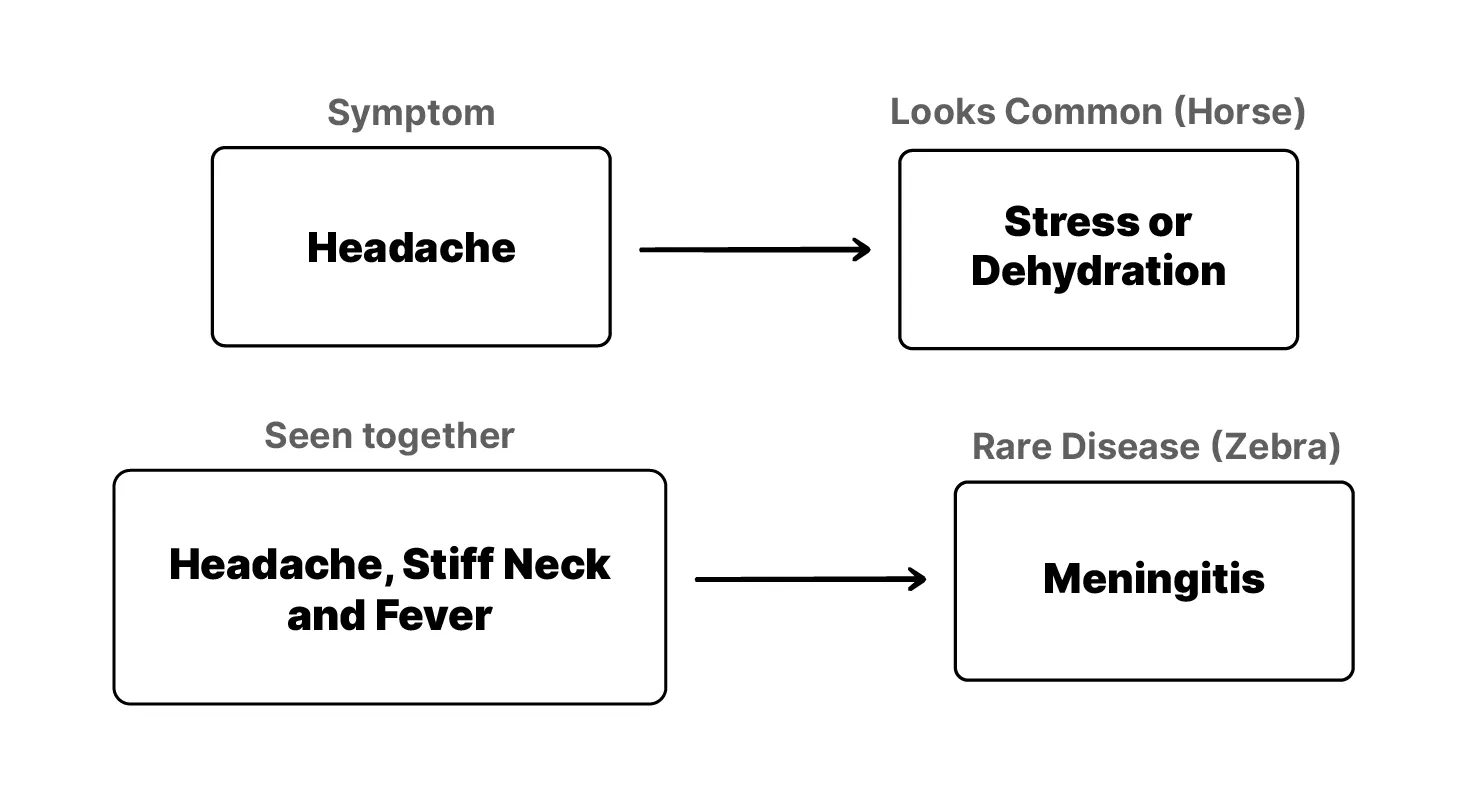
When you hear hoofbeats, think horses, not zebras.
This saying in medicine trains clinicians to reach for the common diagnosis first. Most of the time that’s right. A cough is usually a cold, not something rare. But rare-disease work is the exception. There, you’re looking for the zebra, which is why the zebra has become the symbol for rare disease worldwide.
At Medblocks, we built Tip2Toe, a rare-disease phenotyping app for Karolinska University Hospital, to help clinicians describe what they see in a patient and record it in a structured way that downstream teams can use. (There’s a companion video if you’d rather watch.)
What made it interesting: for the app to run inside a clinician’s EHR at all, we had to write a spec that didn’t exist yet, SMART on openEHR, and Tip2Toe is one of the first real applications running on it. Underneath, we modelled an entire head-to-toe phenotyping questionnaire as a single openEHR archetype but rendered it as thirty-plus clinical sections, with every answer dual-coded: the finding as an HPO term, its presence as SNOMED CT.
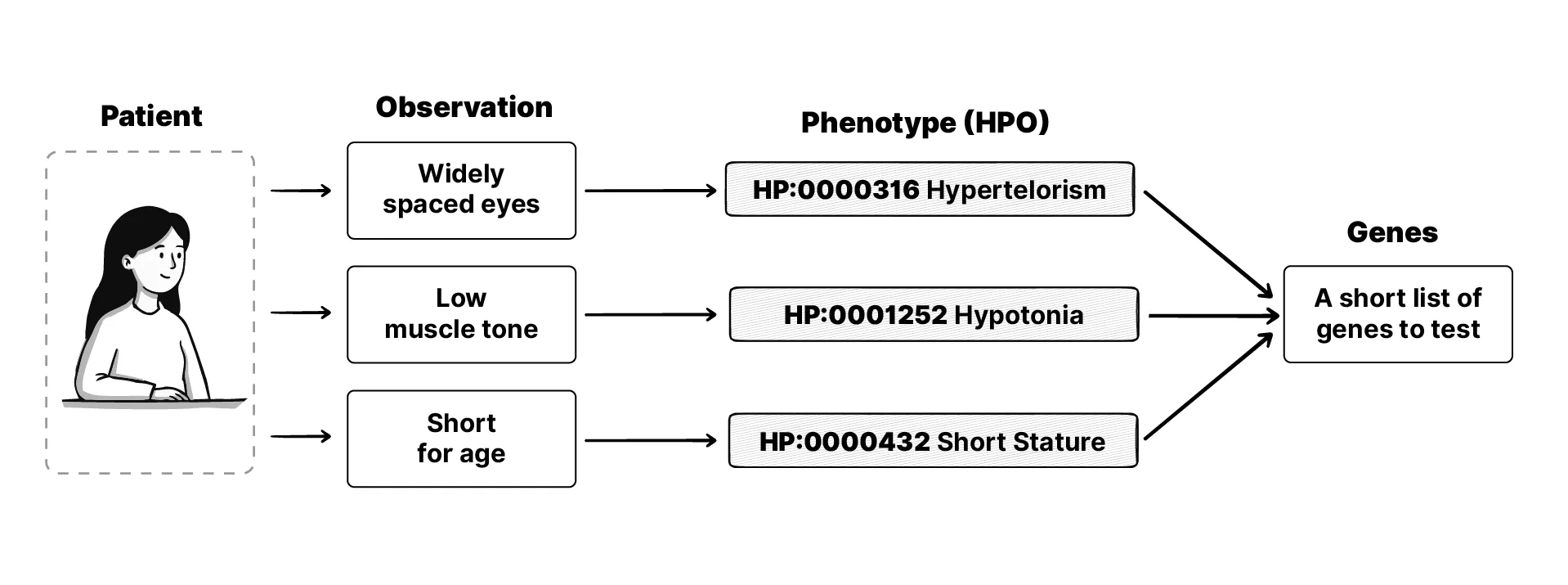
When a child comes in with something unusual (something that might be a rare disease) a clinician examines them and writes down what they see. The medical term for this is phenotyping. The phenotype is everything observable about the patient: how they look, how they’re growing, how they move, what’s typical and what isn’t.
This matters enormously for rare diseases, because phenotypes point to genes. A single symptom might look common, but several of them together can point to something rare. And if a clinician can describe precisely what they’re seeing, you can narrow down which genes to test for, instead of screening the whole genome blindly. The phenotype is the map.
At Karolinska, and almost everywhere else, that map was being written as free text. The clinician would type their observations into the record as a paragraph of prose. And the moment it’s prose, it’s stuck. You can’t easily search it, you can’t filter by it, and when the patient is referred to the genetics lab, the phenotype is hard to even find, let alone act on. You end up with extremely valuable clinical information trapped in a format nobody downstream can really use.
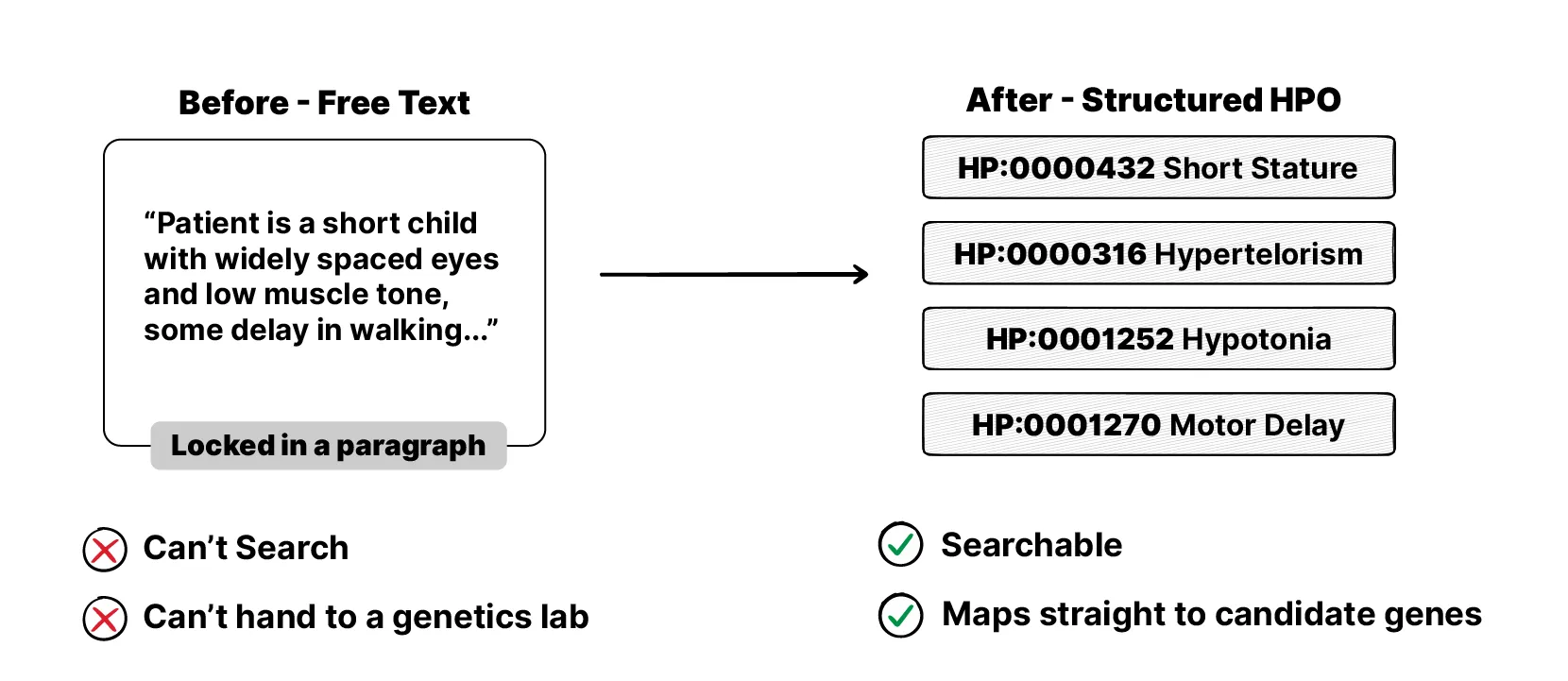
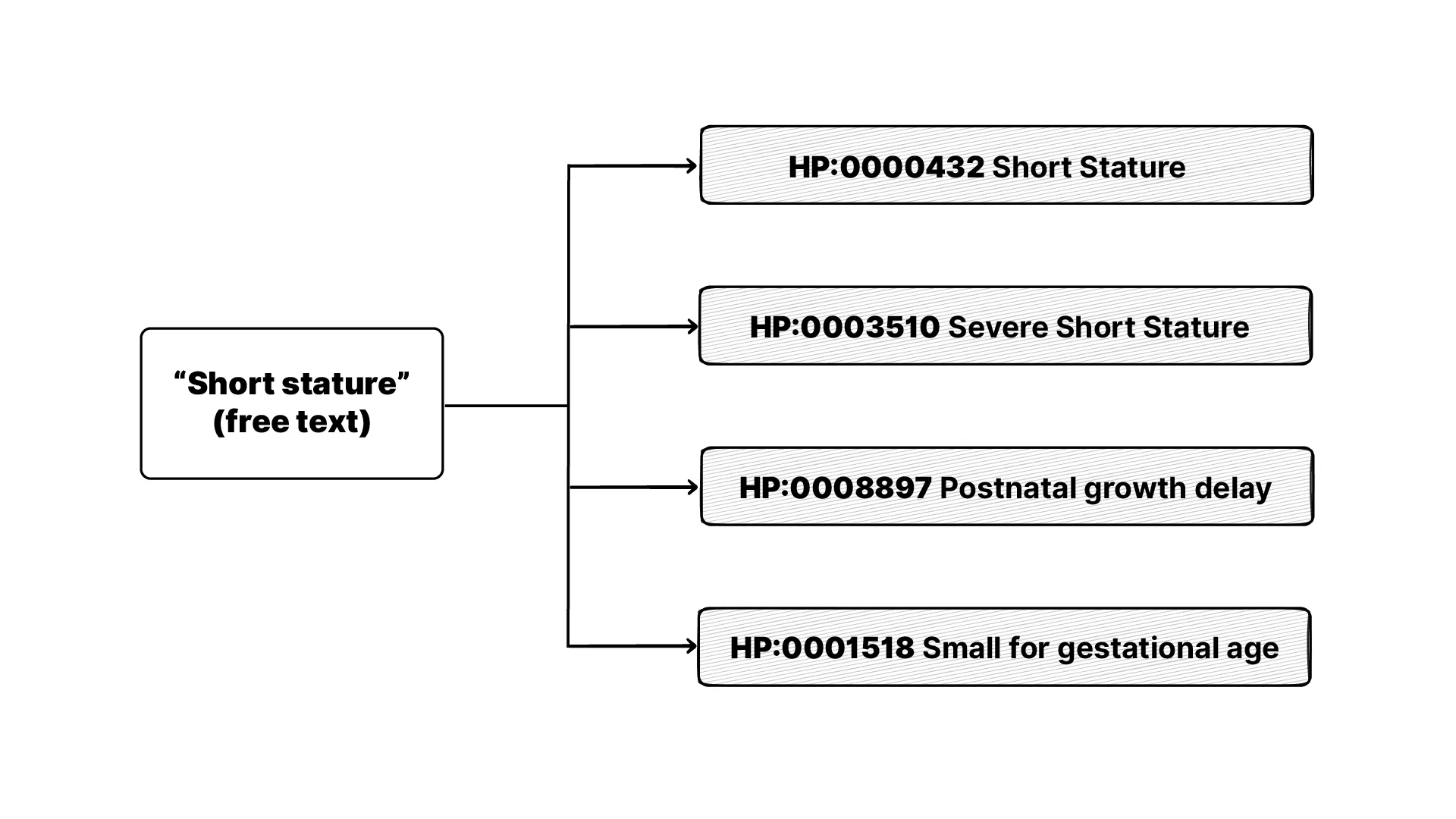
The standard to fix this already exists. It’s called the Human Phenotype Ontology, or HPO. It’s a bit like SNOMED CT or LOINC if you’ve come across those, but specifically for phenotypes. A large, agreed-upon vocabulary where every observable feature has its own code. Instead of writing “the child is unusually short” as text, you record the HPO code for short stature. It’s free, well maintained, and used in rare-disease work all over the world.
What makes HPO powerful is that its codes are linked to the diseases and genes associated with each phenotype. So once a clinician records a handful of phenotypes for a patient, you can look at where they overlap, and that points to the conditions that are likely, and the genes worth screening for. That intersection is the map that tells the lab where to look.
Karolinska was well positioned to use all of this. The hospital had already made a real bet on openEHR, an open standard for storing health data in a structured, vendor-neutral way. Publicly, Karolinska has described basing parts of its Digital Health Platform on openEHR for reasons including faster innovation, better governance and reuse of record data, and the efficiency of storing data in a vendor-neutral, open format. Tip2Toe sits inside that strategy.
So the standard existed, and the platform existed. The gap was the point of care. There was no good way for a clinician to use HPO while they were actually with the patient. Sitting and searching documentation to translate observations into codes by hand is slow. And you can’t simply hand it to AI either. HPO codes are specific, the nuance gets lost, and a model will confidently pick a code that’s close but wrong, so a clinician has to verify it regardless. Faced with that friction, people fall back to free text. That’s the gap we built Tip2Toe to close.
Tip2Toe runs entirely on an openEHR clinical data repository (CDR). In openEHR, you don’t design database tables. You model clinical concepts first, as archetypes: reusable, internationally maintained definitions of things like body weight, family history, or a laboratory result. An application is then a template: a selection and constraint of those archetypes for a specific use case. Because the archetypes are shared and the data conforms to them, what you store is structured and interoperable by default, and it carries terminology bindings such as LOINC and SNOMED CT without any extra work. To understand basic openEHR concepts like archetypes and templates, check out this article called openEHR Archetypes & Templates: Two-Level Model Explained.
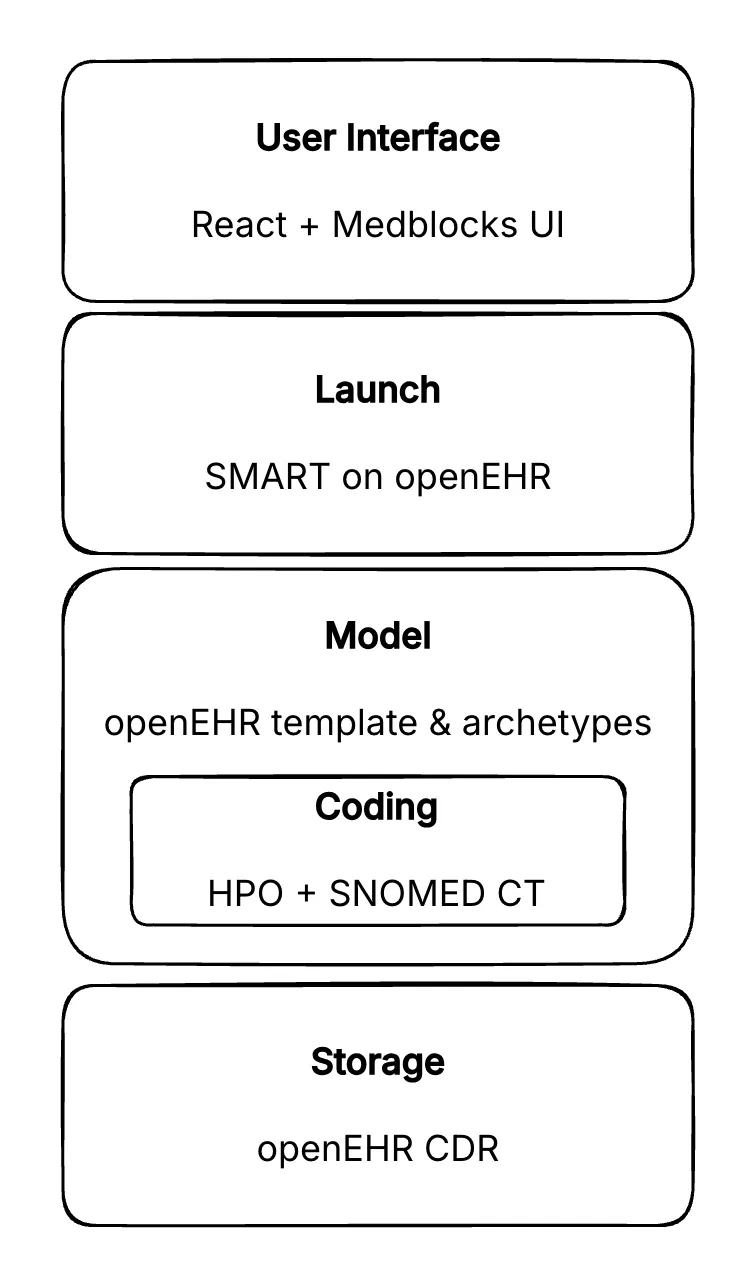
So the first thing we did was model the whole Tip2Toe questionnaire as one openEHR template, reusing standard archetypes wherever they existed before writing any custom ones. Patient demographics, family history, growth measurements, birth summary, prior lab and imaging results, these already exist as published archetypes, so we used them as-is. A child’s weight recorded in Tip2Toe comes out bound to LOINC, the same as it would from any other openEHR system.
A clinician working through Tip2Toe goes from head to toe: eyes, ears, face, nervous system, heart, skeleton, skin, and so on, more than thirty sections in all. In the backend, the entire head-to-toe assessment is a single archetype, OBSERVATION.symptom_sign_screening. The sections exist in the user interface, not in the data model.
Each entry in that archetype has two coded fields: the sign being screened for, and whether it’s present. The sign is an HPO term; the presence value is bound to SNOMED CT. So a single tap on a button produces something like this:
Symptom/sign:
Oligohydramnios → HP:0001562
Present → SCT 373066001
Absent → SCT 373067005
Unknown → SCT 261665006The clinician only ever sees three buttons: Yes, No, Unknown. The dual coding happens underneath: HPO so the phenotype can be matched against disease and gene databases, SNOMED CT so the rest of the record reads it as a clinical finding.
The app ships with a large set of default phenotypes, but no fixed list covers every case. So we added search across the full HPO vocabulary. If a clinician needs a sign that isn’t in a section, they look it up, add it, and it’s stored the same way.
A few things had no standard archetype, such as the patient-facing “This is me” section and the structured prior-genetics workup, so we modelled those ourselves. Most of the questionnaire reused archetypes that already existed.
There’s a tension in openEHR tooling worth being honest about. Normally the form and the template are linked one-to-one. Most vendors give you a form builder that generates the UI directly from the model. It’s convenient, and it’s how a lot of openEHR apps get built. But it means the data model dictates the interface, and you end up with forms that look like forms.
We didn’t want that. The whole point of Tip2Toe was a clinician experience that didn’t feel like data entry with the friendly Yes/No/Unknown buttons, the thirty sections, the inline HPO search. So we built the front end with the Medblocks UI library, which decouples the form from the template entirely. The interface is a normal React app, designed for the clinician; underneath, it still reads and writes valid openEHR compositions against the right archetypes. A good data model and a good user experience, without the model dictating the UI.
An app like Tip2Toe is only useful if it runs inside the clinician’s existing system, launched in context, with the right patient loaded, reading and writing to the shared record. In the FHIR world there’s a well-established way to do this: SMART on FHIR. An app launches securely inside the EHR, learns who the patient and user are, and is granted scoped permission to read and write specific data. It’s how the entire SMART App Launch ecosystem works.
There was no equivalent for openEHR. So, working with the openEHR community, we adapted the same idea into a specification, SMART on openEHR, and Tip2Toe is one of the first real applications running on it.
The shape will be familiar to anyone who knows SMART on FHIR. The app hits a discovery endpoint on the CDR, gets back the URLs it needs, and runs an OAuth2 authorization flow. The scopes are granular, permissions aren’t just “read” or “write”, they can be restricted to a specific template, to specific AQL queries, or to specific operations, and the user sees exactly what they’re granting on a consent screen. The same spec supports both launch types we needed: the patient launching the “This is me” app on its own, and the clinician launching the phenotyping app embedded in their EHR. Both write into the same openEHR CDR.
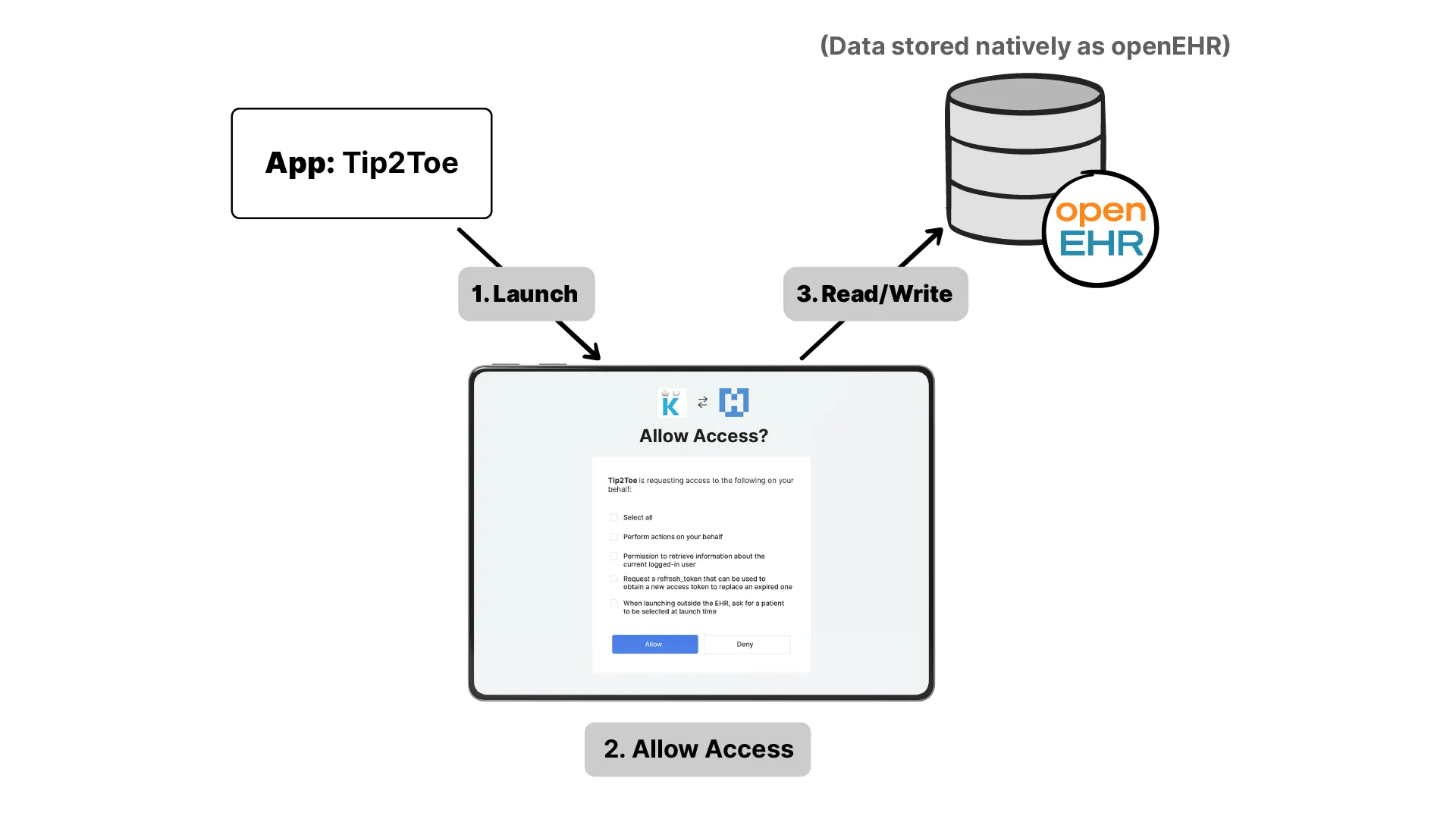
This is also where the vendor-neutral idea pays off in practice. In the deployment we built, Karolinska runs Tip2Toe on a version of the Medblocks platform. But Karolinska has EHR procurements in progress and may move to a different system entirely. Because Tip2Toe is built on SMART on openEHR, that migration doesn’t break it: any platform that speaks openEHR and implements the spec can host the app. It isn’t tied to Medblocks, or to anyone, portable across systems in the same way a SMART on FHIR app is portable across EHRs. That portability is exactly what openEHR’s vendor-neutral promise is meant to deliver, now extended to the application layer.
Tip2Toe is used when a patient is being put forward to the Undiagnosed Diseases Network International (UDNI). UDNI is a global network where experts and centers collaborate on rare cases and share data, because you might be dealing with a disease only a few dozen people in the world have. To submit a patient, you need a completed tip-to-toe questionnaire along with signed consent for things like genome sequencing and data sharing. And UDNI requires that phenotypes be described using a standard ontology, so that everyone is speaking the same language. That requirement is exactly what Tip2Toe satisfies.
The app captures information in two parts. The first is for the patient, and this can be the child, or a parent or guardian filling it in. It’s called “This is me,” and it’s the gentler, human side of things: who the child’s caregivers are, what they like doing, what they need help with. It’s not clinical, and that’s deliberate, it builds a picture of the child as a person before any of the medical detail, and the family contributes to the record directly. Because it’s built as a SMART on openEHR app too, the family just logs in and uses it, and their answers are written into the same openEHR record.
The second part is for the clinician. They open Tip2Toe to find the “This is me” section already filled in, then move into the phenotyping, the head-to-toe assessment described above. The result is one record holding both the human context and the clinical detail.
Go back to the core idea: phenotypes point to genes. As free text, that link is hard to act on. As structured HPO codes, it can be computed directly to narrow down the likely conditions and the genes worth testing. And that matters, because genetic testing isn’t cheap. Testing broadly, where you screen everything, versus testing a focused set, can be something like fifty times the cost.
It saves time too. With the phenotype captured cleanly, downstream teams like genetic counselors aren’t starting from a blank page. We estimated that at somewhere around two to three hours saved per patient.
I want to be straight about those numbers: they’re estimates, not the result of a formal study. This was a pilot, a proof of concept. But we see there’s value in getting the phenotype right and structured, and everything after it becomes faster and cheaper. Which is the core idea behind openEHR anyway: capture information properly once, at the point of care, and reuse it everywhere downstream.
And the part that matters most isn’t the cost. A child with a rare disease can go undiagnosed for years, and some are never diagnosed at all. The difference for that child is enormous. The right diagnosis, the right medication, and an entirely different life. A tool that captures the phenotype properly, at the right moment, in a form that can be read and matched and shared with experts anywhere in the world, is a step toward finding the zebra.
There’s plenty that could make this better.
The obvious next step is not relying on the clinician to remember to open it. Something like CDS Hooks could notice that a case looks unusual and prompt them in the moment. Further out, AI could pre-fill parts of the questionnaire from notes that already exist, so the clinician is reviewing and confirming rather than starting cold, though, as above, mapping free text to exact HPO codes still needs a human in the loop. The idea is to get the clinician into the workflow, prompt them at the right time, and make sense of the codes and the data underneath.
This was a project we did a while back, but it looks a lot like the work we’re doing now. If you’re working on something similar, pulling structured data out of free text, or building on open standards, we’d love to hear from you. Book a call with us directly.
Here's how Medblock's partnered with Clinikk to build a longitudinal, openEHR-based EHR that supports their novel subscription-based care model.

Catalonia wanted an openEHR Clinical Data Repository for 8 million people. Medblocks worked with IBM and vitagroup to design the sync layer for hospitals.

Traditional healthcare software development has significant drawbacks. A platform with standardized features and extensible features might be the right answer.
No comments yet. Be the first to comment!
